Kan AI-training per ongeluk ‘slechte keuzes’ maken?
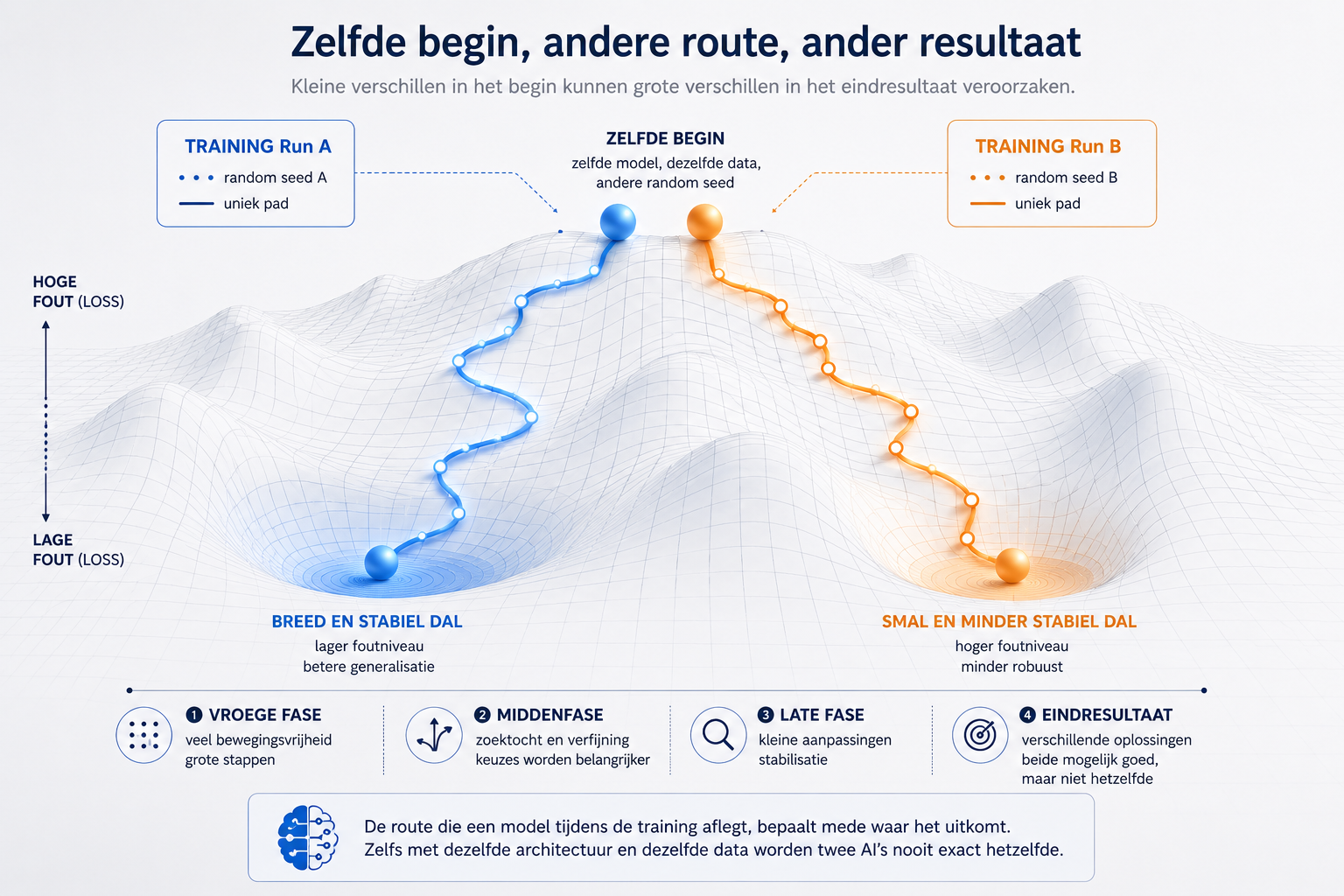
Waarom twee identieke AI’s nooit exact hetzelfde karakter krijgen.
Kan het zo zijn dat twee AI-taalmodellen met dezelfde architectuur en dezelfde trainingsdata toch verschillend eindigen? Kan het ene model toevallig slimmer, efficiënter of flexibeler worden dan het andere, puur doordat het tijdens de training net andere afslagen neemt?
En als dat zo is: betekent dit dan dat een AI-model niet alleen wordt bepaald door zijn ontwerp en data, maar ook door zijn ontwikkelingspad?
Wanneer we een groot AI-taalmodel gaan trainen, begint het in zekere zin blind. In de allereerste fase zijn de interne gewichten willekeurig ingesteld. Het model heeft nog geen idee welke woorden logisch op elkaar volgen. De output is chaos: losse gokjes, zonder begrip, zonder richting.
Maar naarmate het model miljarden teksten verwerkt, verandert dat. De antwoorden worden logischer. Patronen worden sterker. Sommige verbanden worden belangrijker, andere verdwijnen naar de achtergrond.
Het verrassende antwoord op de vraag hierboven is: ja, dat kan. Niet omdat het model bewust verkeerde keuzes maakt, maar omdat het leerproces zelf afhankelijk is van beginwaarden, toeval en de route die het onderweg aflegt.
Het foutenlandschap
Om te begrijpen hoe een AI-model leert, helpt het om je het leerproces voor te stellen als een gigantisch berglandschap. In de AI-wereld wordt dit vaak het loss landscape of optimization landscape genoemd: het foutenlandschap.
Elke plek in dat landschap staat voor een mogelijke toestand van het model. Op de ene plek maakt het model veel fouten. Op een andere plek doet het het al beter. Hoe lager je in het landschap komt, hoe kleiner de fout, oftewel de loss.
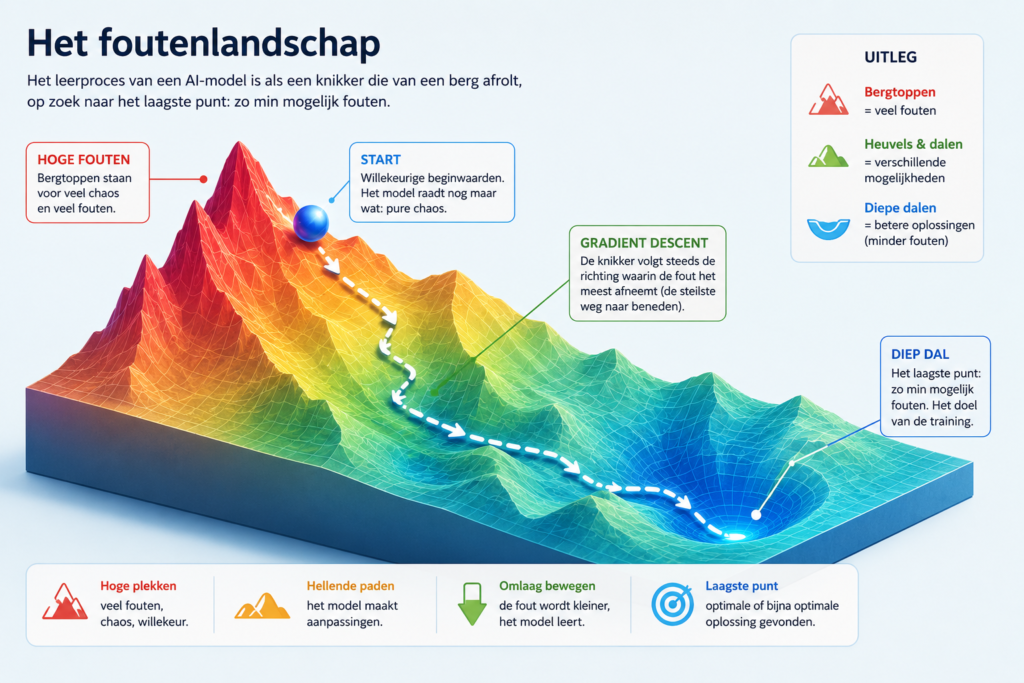
Training is in feite een poging om een digitale knikker door dat landschap te laten rollen. Die knikker zoekt niet bewust naar het beste punt. Hij volgt simpelweg de helling omlaag. In technische termen heet dat gradient descent: telkens worden de interne gewichten een klein beetje aangepast in de richting waarin de fout kleiner wordt.
Er is alleen één probleem: het model ziet niet het hele landschap. Het weet niet waar het diepste dal ligt. Het voelt alleen de helling op de plek waar het zich op dat moment bevindt.
De valkuil van een schijnoplossing
Voordat de training begint, krijgt het model willekeurige startwaarden mee. Dat heet weight initialization. Welke beginwaarden het precies krijgt, hangt samen met de zogenaamde random seed: de bron van willekeur waarmee de training wordt gestart.
Die beginpositie maakt uit. Zet je de knikker net ergens anders neer, dan kan hij een andere route nemen.
Soms komt een model terecht in een oplossing die best aardig werkt, maar niet ideaal is. Klassiek wordt dit vaak een lokaal minimum genoemd: een dalletje waarin de fout lager is dan in de directe omgeving, maar niet zo laag als elders in het landschap.
Bij moderne grote neurale netwerken ligt het vaak nog subtieler. Het probleem is niet altijd een simpel lokaal dalletje. Een model kan ook terechtkomen op een plateau, bij een zadelpunt (saddle point) of in een minder gunstige regio van het landschap. Soms eindigt het in een smal, scherp dal; soms juist in een breder, vlakker dal. Die laatste worden flat minima genoemd, en zulke oplossingen blijken vaak beter te generaliseren: ze werken niet alleen goed op de trainingsdata, maar ook op nieuwe situaties.
Het interessante is dus niet alleen dát het model ergens eindigt, maar ook hóe het daar terechtkomt.
De deuren sluiten zich langzaam
In de vroege fase van de training is er nog veel bewegingsruimte. De stappen die het model zet zijn relatief groot. De learning rate bepaalt hoe groot die stappen zijn. Is die hoog, dan kan de knikker nog flink door het landschap bewegen. Daardoor kan hij soms ook uit een ongunstig dalletje of een slechte regio ontsnappen.
Later in de training wordt die learning rate meestal verlaagd. Dat heet een learning rate schedule. Het model gaat dan steeds kleinere stapjes zetten. De gewichten stabiliseren. Het systeem begint te convergeren: het komt langzaam tot rust.

Daar past ook het begrip simulated annealing mooi bij. Dat is het idee van langzaam afkoelen. Eerst mag een systeem veel bewegen, zodat het niet te snel vastloopt in een slechte oplossing. Daarna wordt de bewegingsvrijheid kleiner, zodat het uiteindelijk stabiel wordt.
Je zou kunnen zeggen: in het begin staan de deuren nog open. Later sluiten ze zich langzaam.
Niet omdat het model letterlijk bevriest, maar omdat grote veranderingen steeds riskanter worden. Als een model eenmaal een complexe interne structuur heeft opgebouwd, kun je niet zomaar alles omgooien zonder ook veel bruikbare patronen kapot te maken.
Waarom twee identieke AI’s toch verschillend worden
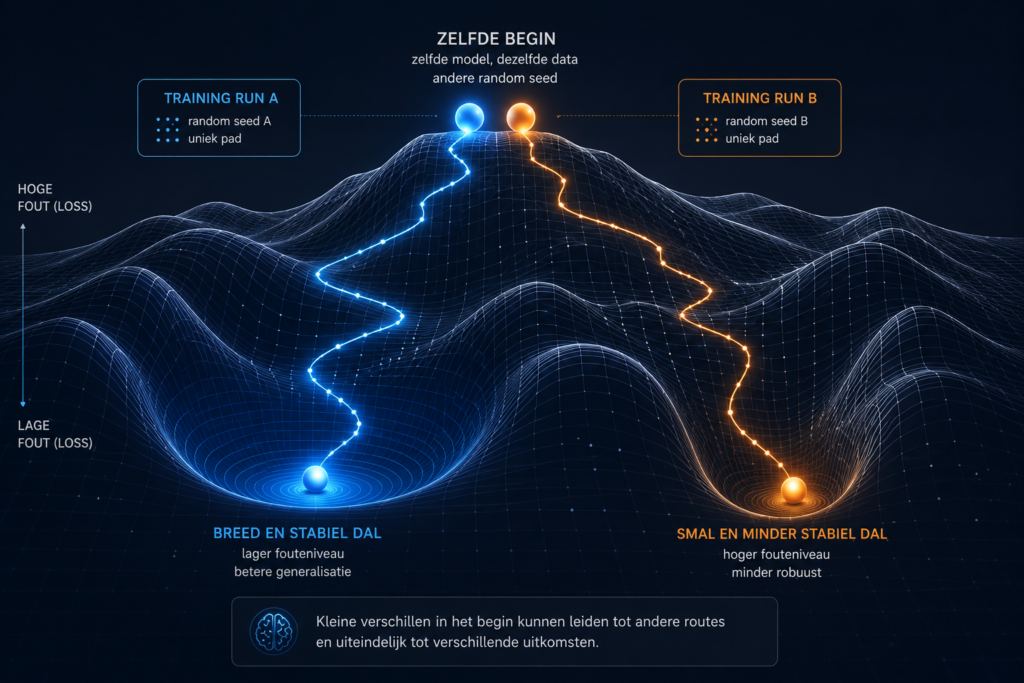
Dit verklaart waarom twee trainingen met dezelfde architectuur en dezelfde data toch niet exact hetzelfde model opleveren. Alleen al een andere random seed kan genoeg zijn om het model net anders te laten starten. Vanaf daar volgt het een net andere route door het foutenlandschap.
Zo ontstaan subtiele verschillen. Het ene model kan iets scherper zijn in bepaalde redeneringen. Het andere kan net andere blinde vlekken hebben. Niet omdat de data anders waren, maar omdat de route door het landschap anders verliep.
In de AI-wereld noemen we zo’n gebied dat naar een bepaalde oplossing trekt soms een basin of attraction: een aantrekkingsgebied. Als je in zo’n gebied begint, is de kans groot dat je uiteindelijk in hetzelfde dal terechtkomt. Begin je net buiten dat gebied, dan kan het eindpunt heel anders worden.
Dat maakt training minder mechanisch dan je misschien zou denken. Computers rekenen exact, maar grote neurale netwerken ontwikkelen zich via een proces waarin toeval, beginpositie en timing een rol spelen.
Waarom trainingen soms worden stopgezet
Bij grote AI-trainingen kijken onderzoekers voortdurend naar de ontwikkeling van het model. Daalt de loss zoals verwacht? Blijft de training stabiel? Ontstaan er geen vreemde problemen, zoals instabiele gradiënten of slechte convergentie?
Als een training vroeg laat zien dat het model op een ongunstig pad zit, kan het gebeuren dat zo’n trainingsrun wordt stopgezet. Dat heeft niet altijd letterlijk te maken met één lokaal minimum. Het kan ook gaan om instabiliteit, hardwareproblemen of een model dat duidelijk minder goed leert dan verwacht.
Maar het onderliggende idee blijft hetzelfde: de vroege fase is belangrijk. Als een model in het begin een ongunstige route neemt, is dat later niet altijd volledig te herstellen.
Padafhankelijkheid
Daarmee raakt AI aan een veel breder principe: padafhankelijkheid (path dependence).
Padafhankelijkheid betekent dat de uitkomst van een proces niet alleen afhangt van het einddoel, maar ook van de route ernaartoe. Kleine toevalligheden vroeg in het proces kunnen later grote gevolgen hebben. Je ziet dat in de economie, evolutiebiologie, ontwikkelingspsychologie en dus ook bij het trainen van neurale netwerken.
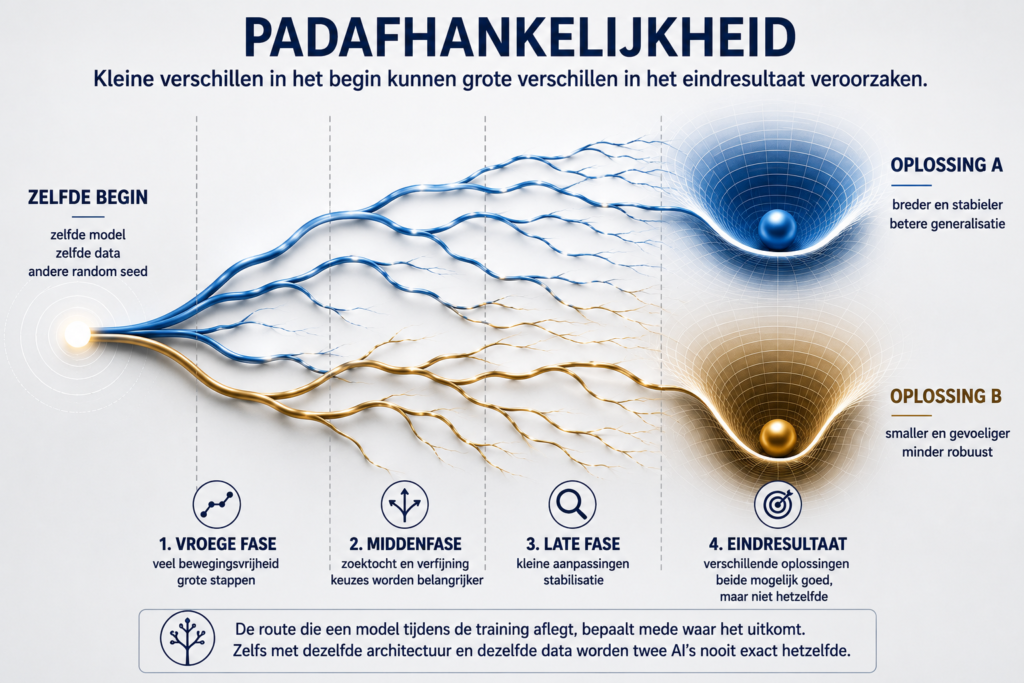
Een taalmodel wordt niet simpelweg steeds slimmer op één rechte lijn omhoog. Het ontwikkelt zich via afslagen, correcties, versnellingen, vertragingen en toevallige beginposities. Sommige routes leiden naar brede, robuuste oplossingen. Andere routes leveren een model op dat prima functioneert, maar nét iets minder flexibel of efficiënt is dan het had kunnen zijn.
Dat is misschien wel het meest fascinerende: zelfs bij iets dat volledig uit wiskunde bestaat, speelt geschiedenis een rol.
Een AI-model heeft geen jeugd zoals een mens. Het heeft geen herinneringen, geen ervaringen en geen bewustzijn. Maar het heeft wél een ontwikkelingspad. En dat pad laat sporen na.
Twee identieke AI’s worden daardoor nooit helemaal hetzelfde. Niet omdat ze een ziel hebben, maar omdat ook in kunstmatige intelligentie geldt dat de weg die je aflegt mede bepaalt waar je uiteindelijk uitkomt.
Related Posts
