Graceful degradation: wat gebeurt er als 10 procent van een AI-taalmodel uitvalt?

Informatie in een AI-taalmodel zit niet op één plek. Er is geen vaste opslagplaats waarin staat dat Parijs de hoofdstad van Frankrijk is, geen afzonderlijk onderdeel dat grammatica bewaart en geen specifieke locatie voor begrippen als ‘verdriet’, ‘democratie’ of ‘hond’.
In plaats daarvan is kennis verspreid over miljarden gewichten: kleine numerieke waarden die samen bepalen hoe informatie door het netwerk stroomt. Elk gewicht draagt een minuscuul beetje bij aan ontelbaar veel verschillende concepten tegelijk. In de AI-wereld wordt dit vaak aangeduid als distributed representations: gedistribueerde representaties. Kennis is niet lokaal opgeslagen, maar verdeeld over het netwerk.
Dat roept een interessante vraag op: wat gebeurt er als 10 procent van zo’n taalmodel uitvalt? Verliest het model dan 10 procent van zijn kennis? Gaat het slechter redeneren? Of blijft het verrassend goed functioneren?
Kennis is geen verzameling feiten
Veel mensen stellen zich een taalmodel voor als een enorme database. Dat is begrijpelijk, maar niet hoe een LLM werkt. In een database staat ieder gegeven op een vaste plaats. Als een bestand beschadigd raakt, ben je precies dat stukje informatie kwijt.
Een taalmodel werkt fundamenteel anders. De kennis ligt niet vast op één locatie, maar is verdeeld over een enorm netwerk. Elk gewicht draagt tegelijkertijd een heel klein beetje bij aan talloze verschillende begrippen, feiten en verbanden. Andersom wordt elk concept ondersteund door een enorm aantal gewichten.
Je zou dit ook distributed memory kunnen noemen: een vorm van geheugen waarin informatie niet op één plek ligt, maar verspreid aanwezig is in patronen van verbindingen. Kennis bestaat dus niet uit losse feiten, maar uit patronen die gezamenlijk betekenis vormen.
Graceful degradation: geleidelijk minder scherp
Juist doordat kennis zo verspreid is opgeslagen, kan een taalmodel behoorlijk veel schade verdragen. Wanneer onderzoekers willekeurig een deel van de gewichten uitschakelen, blijft het model vaak verrassend goed presteren. Het wordt niet ineens 10 procent dommer wanneer 10 procent van de gewichten wegvalt.
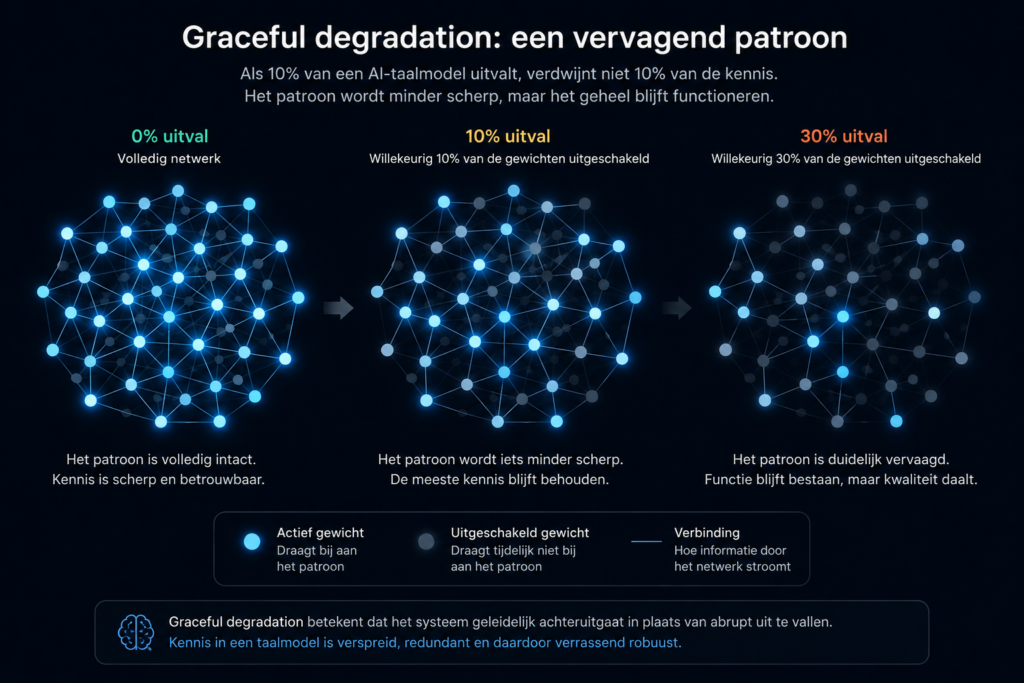
Dit verschijnsel heet graceful degradation: een systeem stopt niet abrupt met functioneren, maar gaat geleidelijk achteruit. De berekeningen duren bovendien niet automatisch korter of langer. De architectuur van het netwerk verandert immers niet.
Wat wel verandert, is de kwaliteit van de antwoorden. Complexe redeneringen worden minder betrouwbaar, zeldzame feiten raken eerder verloren, de kans op hallucinaties neemt toe en soms ontstaan subtiele logische of grammaticale fouten. Het model wordt niet zozeer onwetend, maar eerder minder scherp.
Redundantie en fault tolerance
De reden dat het model blijft functioneren, is redundantie. Informatie is niet afhankelijk van één specifieke plek of route. Dezelfde kennis is op meerdere manieren in het netwerk vertegenwoordigd. Daardoor kan een deel van het netwerk uitvallen zonder dat alles meteen verloren gaat.
In de informatica wordt dit ook wel fault tolerance genoemd: het vermogen van een systeem om te blijven functioneren ondanks fouten, defecten of uitval. Bij een taalmodel betekent dit niet dat er letterlijk kopieën van feiten bestaan. Het is subtieler. De kennis zit verweven in patronen, waardoor de rest van het netwerk vaak nog genoeg structuur bevat om tot een bruikbaar antwoord te komen.
Pruning: hoeveel kan er eigenlijk weg?
Een verwant begrip is pruning. Bij pruning worden delen van een neuraal netwerk bewust verwijderd of op nul gezet. Onderzoekers doen dit bijvoorbeeld om modellen kleiner, efficiënter of beter inzetbaar te maken.
Dat klinkt radicaal, maar vaak blijkt dat een netwerk veel meer kan missen dan je zou verwachten. Niet elk gewicht is even belangrijk. Sommige delen dragen weinig bij, terwijl andere delen juist cruciaal zijn.
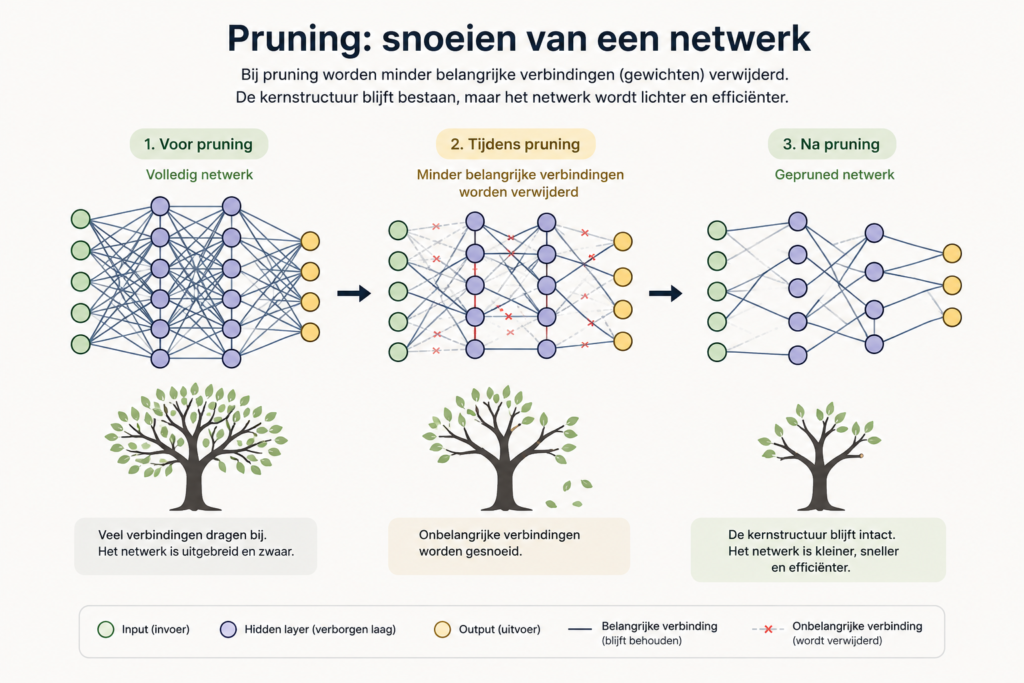
Dit laat mooi zien dat een taalmodel niet werkt als een kast vol losse feiten. Als je daar een plank uit trekt, ben je alles op die plank kwijt. Bij een taalmodel ligt informatie veel meer verspreid.
Is dit plasticiteit?
Op het eerste gezicht lijkt dat misschien op het menselijk brein. Ook wij kunnen vaak kleine beschadigingen opvangen zonder dat dit direct merkbaar is. Toch is er een belangrijk verschil.
Ons brein beschikt over neuroplasticiteit: het vermogen om verbindingen aan te passen en functies deels door andere hersengebieden te laten overnemen. Vooral na schade of intensief oefenen kan het brein zichzelf gedeeltelijk reorganiseren.
Een standaard taalmodel kan dat tijdens gebruik niet. Zodra het model is getraind, liggen de gewichten vast. Als er daarna iets uitvalt, herstelt het zichzelf niet. Het netwerk past zich niet spontaan aan en legt geen nieuwe verbindingen aan.
De robuustheid van een taalmodel komt dus niet voort uit actief herstel, maar uit de manier waarop de kennis al vóór die tijd over het netwerk is verdeeld.
Database, brein en taalmodel: drie manieren waarop kennis beschadigd kan raken:
| Systeem | Waar zit kennis? | Wat gebeurt er bij schade? | Herstel of aanpassing? |
|---|---|---|---|
| Database | Op vaste locaties, zoals bestanden, velden of records. | Specifieke gegevens raken beschadigd of verdwijnen. | Alleen via back-up, reparatie of handmatige correctie. |
| Menselijk brein | Verspreid over netwerken, maar ook deels gespecialiseerd per gebied. | Soms merkbare uitval, soms gedeeltelijke compensatie. | Ja, door neuroplasticiteit: het brein kan verbindingen aanpassen en functies deels herverdelen. |
| AI-taalmodel | Verspreid over miljarden gewichten en patronen van activatie. | Geen abrupt kennisverlies, maar geleidelijke kwaliteitsdaling: minder scherp, meer fouten. | Niet tijdens gebruik. Alleen tijdens training of hertraining kunnen gewichten opnieuw worden aangepast. |
Dropout: oefenen met uitval
Toch zit er tijdens de training iets in dat op plasticiteit lijkt. Onderzoekers gebruiken regelmatig een techniek die dropout heet. Daarbij wordt tijdens iedere trainingsstap willekeurig een deel van de neuronen tijdelijk uitgeschakeld.
Hierdoor leert het model dat het nooit afhankelijk mag worden van één specifieke route door het netwerk. Dezelfde kennis moet via meerdere wegen bereikbaar blijven. Je zou kunnen zeggen dat het model tijdens het leren wordt voorbereid op toekomstige schade.
Dropout stimuleert dus distributed representations, redundantie en fault tolerance. Het helpt een netwerk om later graceful te degraderen in plaats van direct in te storten. Dat is geen plasticiteit tijdens het gebruik, maar wel een manier om een robuust netwerk op te bouwen.
Tussen een database en een brein
Misschien moeten we daarom stoppen met AI te vergelijken met een database. Daarvoor is een taalmodel veel te flexibel. Maar het is ook geen menselijk brein. Daarvoor ontbreekt juist het vermogen om zichzelf tijdens het gebruik voortdurend aan te passen.
Een taalmodel bevindt zich ergens tussen die twee uitersten. De kennis is niet opgeslagen als losse feiten, maar als een ingewikkeld netwerk van patronen. Daardoor kan het verrassend veel schade opvangen. Tegelijkertijd mist het nog iets fundamenteels: het vermogen om zichzelf na die schade opnieuw te organiseren.
Misschien is dat wel een van de grootste verschillen tussen de kunstmatige intelligentie van vandaag en de biologische intelligentie waarmee wij denken. AI vergeet niet zoals een database gegevens verliest. Het vervaagt eerder. En juist dat maakt graceful degradation zo’n interessant begrip: het laat zien dat kennis in AI niet breekt als een bestand, maar langzaam minder scherp wordt als een patroon dat deels beschadigd raakt.
Related Posts