Denkt AI in het Nederlands? Over AI en betekenisruimte

Wat mij enorm fascineert aan AI is niet hoe het antwoord geeft, maar hoe het begrijpt waar mijn vraag eigenlijk over gaat.
We zeggen vaak dat AI steeds het meest waarschijnlijke volgende woord voorspelt. Dat klopt ook. Maar volgens mij is dat pas de laatste stap.
Voordat AI überhaupt een antwoord kan formuleren, moet het eerst proberen te begrijpen wat ik bedoel. Niet alleen de woorden die ik gebruik, maar ook de context en de betekenis daarvan. Onder de motorkap gebeurt daarbij ontzettend veel. Moderne AI-modellen zetten woorden om in wiskundige representaties, waarbij woorden met een vergelijkbare betekenis dichter bij elkaar komen te liggen. Vervolgens gebruiken ze mechanismen zoals self-attention om te bepalen welke woorden en begrippen in een vraag belangrijk zijn en hoe ze met elkaar samenhangen. Op basis daarvan ontstaat een contextafhankelijke representatie van wat mijn vraag waarschijnlijk betekent. Pas daarna begint AI met het formuleren van een antwoord, woord voor woord.
Juist dat proces fascineert me. Niet zozeer de output, maar de interpretatie die daaraan voorafgaat.
Hoe bepaalt AI eigenlijk waar mijn vraag terechtkomt? Hoe ‘weet’ het systeem dat ik dit bedoel en niet iets net anders? Hoe ziet zo’n betekenisruimte er eigenlijk uit?
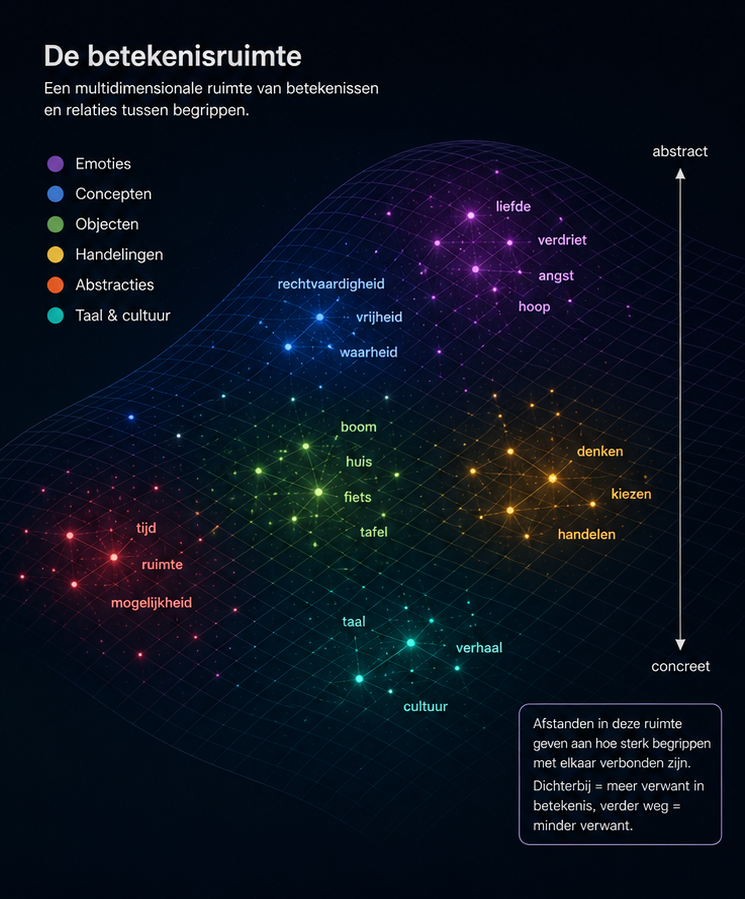
Natuurlijk bestaat die betekenisruimte niet letterlijk. Uiteindelijk zijn het enorme hoeveelheden getallen en wiskundige relaties. Maar om daarover na te denken helpt een metafoor mij enorm.
Ik stel me die betekenisruimte voor als een gigantische multidimensionale ruimte waarin alle begrippen en betekenissen met elkaar verbonden zijn. Niet als woorden in een woordenboek, maar als een enorm landschap waarin sommige begrippen dicht bij elkaar liggen en andere juist heel ver uit elkaar. Vanuit dat beeld begon ik me af te vragen wat er gebeurt wanneer verschillende talen zich allemaal in diezelfde betekenisruimte bevinden.
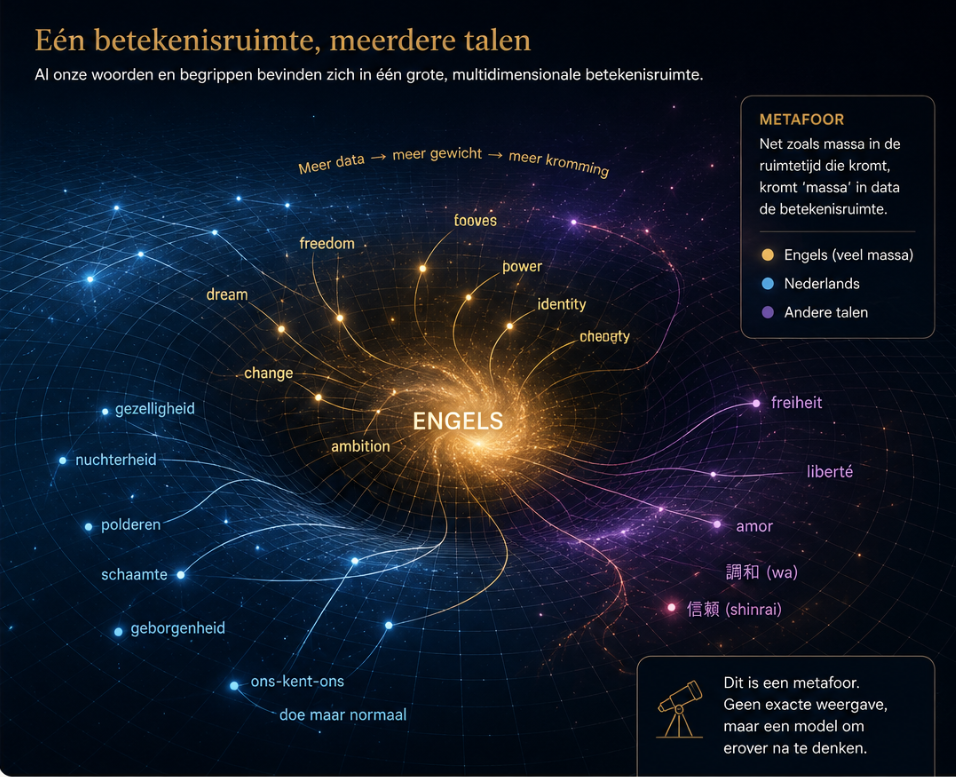
Eén betekenisruimte, meerdere talen
Laten we er even van uitgaan dat alle talen in één grote betekenisruimte zitten. Dan wordt de vraag: hoe verhouden die talen zich tot elkaar?
Mijn aanname is simpel: net als in een echte ruimtetijdstructuur is er zwaartekracht. Niet letterlijk natuurlijk, maar als metafoor. Er is een kracht die de ruimte kromt en die andere elementen, lijnen en betekenissen naar zich toetrekt.
Een taal die veel vaker voorkomt in de trainingsdata van een AI-model krijgt in deze metafoor meer massa. En meer massa betekent meer invloed op de vorm van de betekenisruimte. Dat laat nu precies het interessante punt zien bij Engels.
Engels komt veel vaker voor in de data waarop grote AI-modellen zijn getraind dan Nederlands. Daardoor heeft Engels in die betekenisruimte als het ware meer gewicht. Het vormt het veld sterker. Het trekt meer verbindingen naar zich toe. Het bepaalt vaker hoe begrippen zich tot elkaar verhouden.
Nederlands bevindt zich dan niet in een volledig eigen, afgescheiden ruimte. Het beweegt mee in een landschap dat voor een groot deel al door Engels is gevormd. En als dat klopt, kan dat gevolgen hebben voor het Nederlands. Niet alleen voor de woorden die we gebruiken, maar ook voor de betekenis van die woorden.
Misschien gaan we niet alleen meer Engelse woorden gebruiken. Misschien gebeurt er iets subtielers. Misschien blijven we gewoon Nederlandse woorden gebruiken, maar verschuift langzaam de plek die die woorden innemen ten opzichte van andere begrippen.
Hun associaties, gevoelswaarde en onderlinge relaties kunnen dan steeds iets meer gaan lijken op de Engelstalige betekenisstructuur waarop AI grotendeels is gebaseerd. Dan verengelst Nederlands niet alleen aan de oppervlakte, maar ook in betekenis.
Een voorbeeld
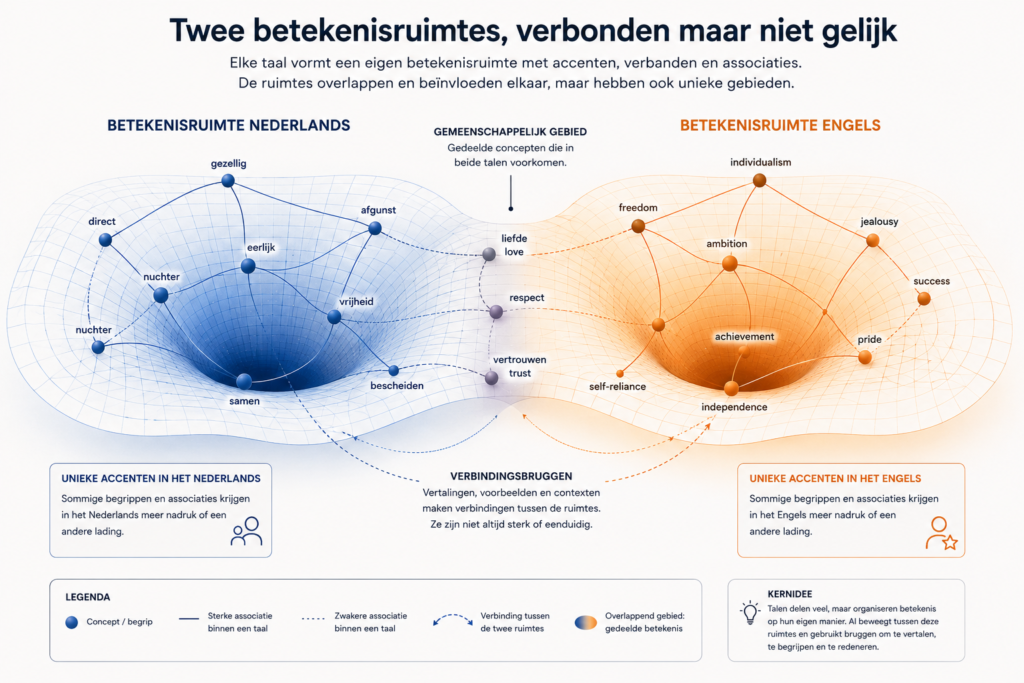
Een goed voorbeeld hiervan zit in de taal van emoties. In het Engels wordt vaak onderscheid gemaakt tussen jealousy en envy. In het Nederlands kom je al snel uit op jaloezie en afgunst. Officieel zijn dat bruikbare vertalingen, maar gevoelsmatig vallen ze niet precies samen. Afgunst klinkt in het Nederlands veel zwaarder dan envy in het Engels, terwijl jaloezie weer niet altijd dezelfde lading dekt. De woorden liggen dicht bij elkaar, maar ze bevinden zich niet op exact dezelfde plek in de betekenisruimte.
Dat verschil is belangrijk. Als AI een Nederlands antwoord formuleert, is de vraag niet alleen of het de juiste Nederlandse woorden kiest, maar ook vanuit welke betekenisstructuur die woorden worden gekozen. Vertrekt het vanuit een echt Nederlandse gevoelswaarde, of vanuit een betekenisruimte die grotendeels door Engels is gevormd en waar vervolgens Nederlandse woorden bij worden gezocht?
Voor typisch Nederlandse onderwerpen zal dit effect waarschijnlijk kleiner zijn. Begrippen als de Elfstedentocht, de koning, stroopwafels, fietsen door de stad of de Nederlandse poldercultuur hebben een sterke eigen context. Daar is de Nederlandse betekenislaag duidelijker aanwezig. Maar bij universele begrippen zoals liefde, schaamte, vrijheid, identiteit, rechtvaardigheid of jaloezie kan de invloed van het Engels veel groter zijn.
Juist daar kan het Nederlands subtiel gaan verschuiven. Niet doordat Nederlandse woorden verdwijnen, maar doordat hun gevoelswaarde, associaties en onderlinge relaties langzaam meer gaan lijken op de Engelstalige betekenisstructuur waarop AI grotendeels is gebaseerd. Dan verandert niet alleen de taal waarin AI antwoord geeft, maar ook de manier waarop betekenis wordt gevormd.
Meerdere betekenisruimtes?
Uiteindelijk brengt deze gedachte me bij een vraag die ik misschien nog wel interessanter vind dan mijn oorspronkelijke idee. Bestaat er eigenlijk één grote betekenisruimte waarin alle talen samenkomen? Of heeft iedere taal toch een eigen betekenislaag die gedeeltelijk zelfstandig functioneert? Of bestaan beide tegelijk?
En als er inderdaad verschillende lagen zijn, hoe zijn die dan ontstaan? Is dat een organisch gevolg van het leerproces, waarbij het model zelf patronen ontdekt en talen op een bepaalde manier organiseert? Of hebben de ontwerpers van taalmodellen daar bewust in gestuurd? Misschien allebei.
Ik heb inmiddels allerlei ideeën over hoe dit zou kunnen werken, maar ik ben vooral benieuwd in hoeverre die overeenkomen met hoe moderne taalmodellen daadwerkelijk zijn opgebouwd. Dat is precies waar ik de komende tijd verder in wil duiken.
Wordt vervolgd…
Related Posts
